
What is Encoding?
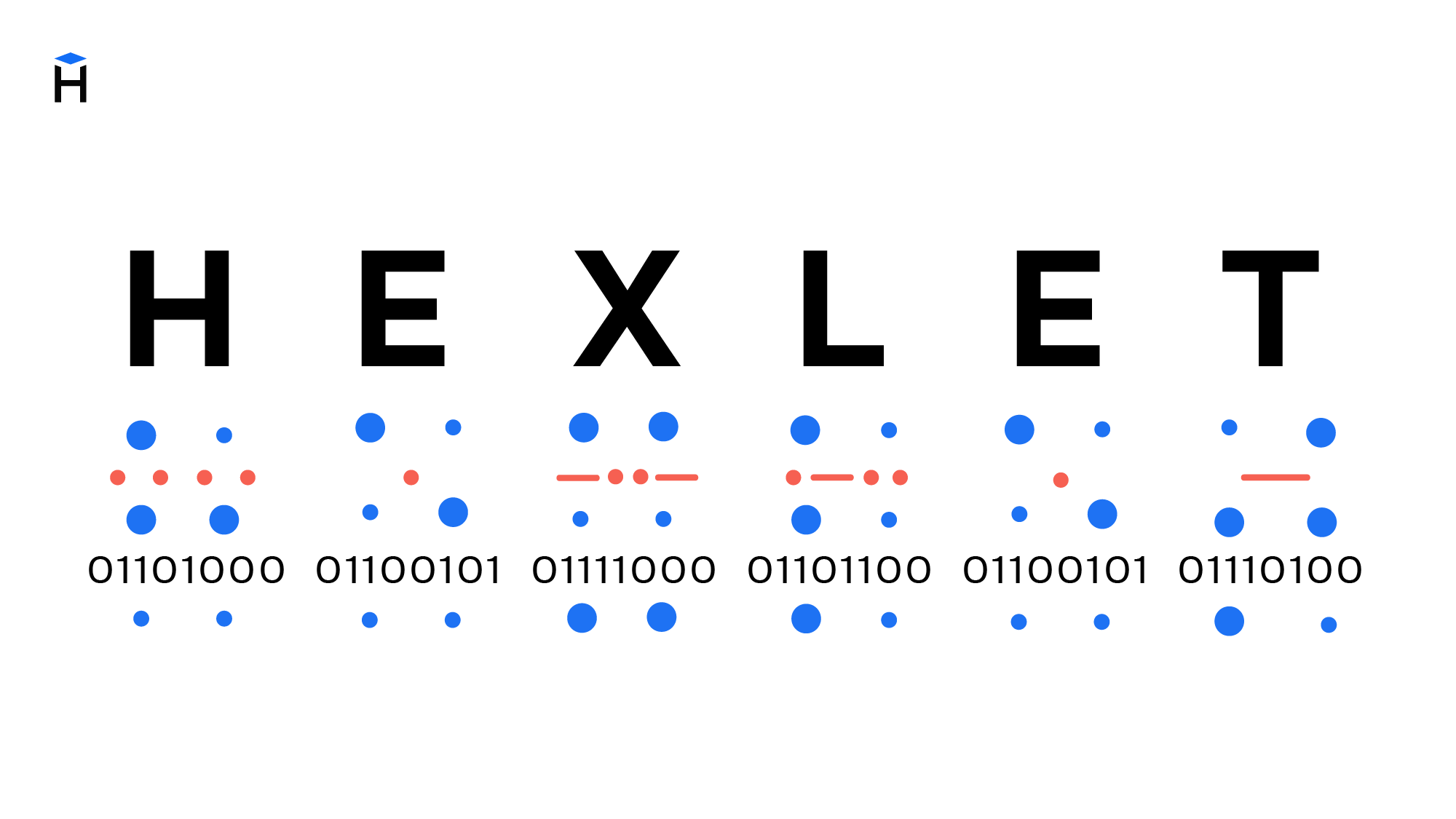
- Why are encodings so important?
- History of encodings
- ASCII as the first information encoding standard
- Switching to Unicode
- Unicode-based encodings
- Summary
Why are encodings so important?
Computers use text: news feeds, stock exchanges, messages on social media and messengers, banking applications, and more. Today, we cannot imagine life without the exchange of information. It wasn't always like this, though. Computers learned to work with text thanks to the emergence of encodings. Encodings have come a long way from character tables created specifically for each computer to a united worldwide encoding.
Today Unicode is the leading character encoding standard that includes characters from almost all of the living languages of the world. Unicode is applied wherever there is text. Information on social media, database entries, computer programs, and mobile applications — all this works with the use of Unicode.
This guide will cover how Unicode appeared and what problems it resolves today. We will find out how information was stored and transmitted before the introduction of the universal character representation standard, and also look at the examples of Unicode-based encodings.
History of encodings
Originally, computers were intended to speed up and automate calculations. The word “computer” itself could be translated to some languages as "a calculator", and in the 20th century in the USSR, the term "automatic computing engine" was in use.
All that computers operate on are numbers. And defense enterprises became the main customer and driving force behind the appearance of first models. They used computers to calculate the flight variables of ballistic missiles, airplanes, and satellites. In the 1950s, the computating power of computers was also used for:
- weather forecasting
- experimental and theoretical physics
- salary calculation and accounting (for example, the LEO computer was used by a company that owned a chain of tea shops)
- forecasting the results of the US presidential election (UNIVAC in 1952, the first commercially produced digital computer)
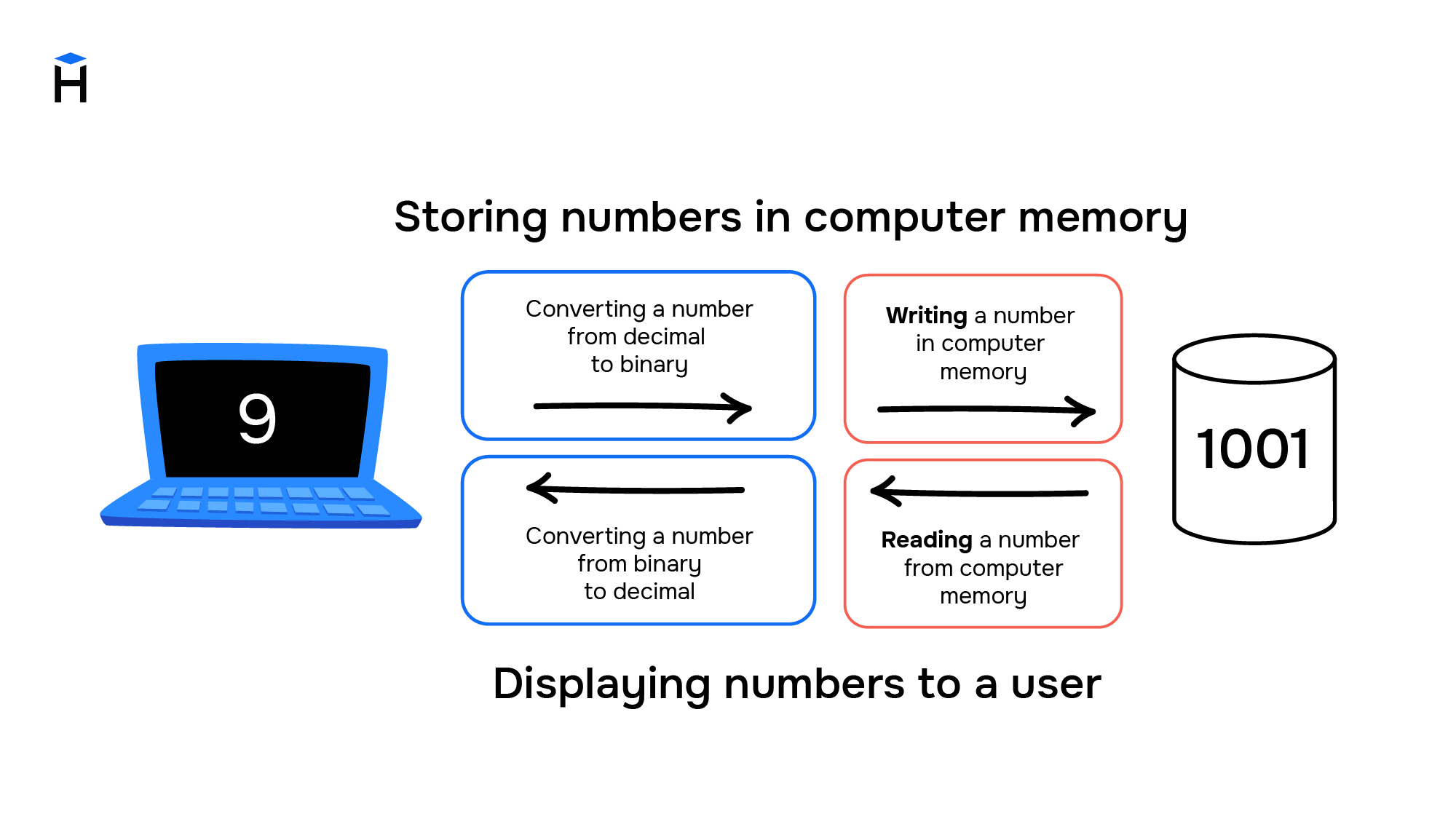
Computers and numbers
The initial goals of creating computers resulted in an architecture intended for working with numbers. They are stored on the computer as follows:
- A number from the decimal numeral system is converted to binary, which uses only two symbols: "0" (zero) and "1" (one). For instance, the binary number system allows for the representation of 3 as 11 and 9 as 1001.
- As a result, a set of zeros and ones are stored in computer memory cells. For example, the presence of electric current on a memory element means one, and its absence means zero
In the late 1950s, incandescent lamps were replaced with semiconductor elements (transistors and diodes). This made it possible to reduce the size of computers, increase the speed and reliability of calculations, and also affect the final cost. Additionally, serial computers — not a personal ones yet — started to appear with semiconductors, whereas the early computers were expensive and could only be purchased by states or huge corporations.
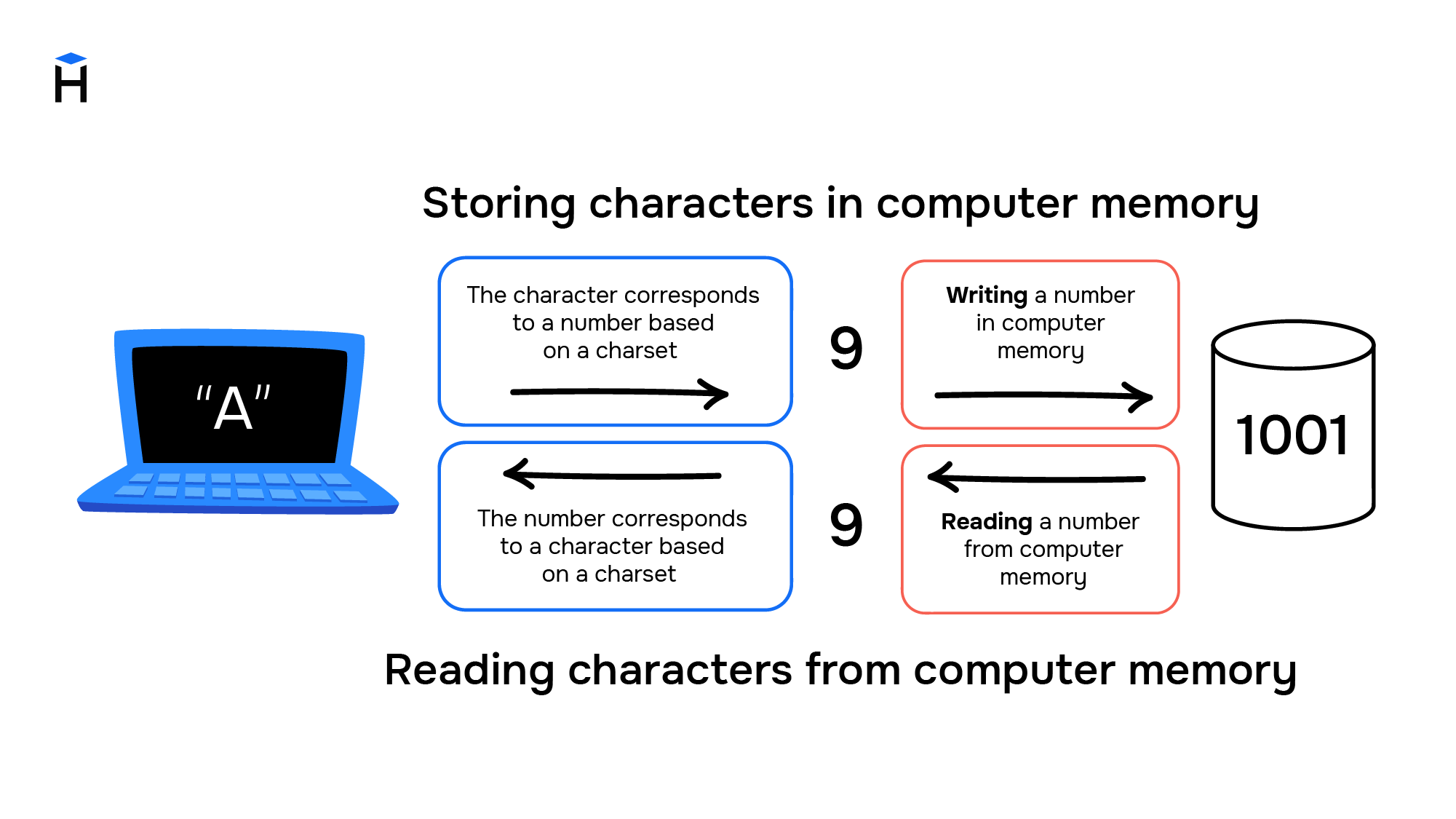
Computers and characters
Over time, computers started to be used to solve not only computational or mathematical problems: it became necessary to process textual information. But the situation was a bit more complicated with non-numeric characters. Characters are graphical objects, even the same letter "a" can be represented by two different characters: "a" and "A" due to case sensitivity.
The number "one" can be represented by various characters as well. It can be the Arabic numeral "1" or the Roman numeral "I". The value of the number doesn't change; only the characters do.
Computers were designed to work with numbers, and they cannot store characters, so while entering information all characters are converted into numbers and stored in the computer's memory as ordinary numbers. And to display information, numbers are converted back into characters.
The rules for converting characters and numbers were written as a mapping table (also known as character encoding form, character map or character set providing character encoding in general). Following it, each computer had to have a unique input/output device (for example, a keyboard and a printer).
Popularizing computers
In the early 1960s, computers were incompatible with each other, even within the same manufacturing company. For example, IBM corporation had about 20 design bureaus, each of which was developing its own computer device. Such computers weren’t versatile but were supposed to solve specific tasks. The required character set and input/output device were created for each task.
These years saw the emergence of the first interconnected computer networks. The Semi-Automatic Ground Environment System (SAGE), which was developed in 1958, connected the radar stations in the United States and Canada to form the first significant computer network. They needed to have the same character tables in order to use the calculations performed on computers connected to the same network.
In 1962, IBM formed two main principles for its production development:
- Computers should be universal. This meant the transition from the production of highly specialized computers to those that could solve different tasks
- Computers should be compatible with one another; that is, data from one computer should be usable on another
As a result, in 1965, IBM System/360 computers flooded the market. There was a range of six models composed of compatible modules. The models differed in performance and price, allowing customers to choose from. The modularity of the systems resulted in an emergence of a new industry — the production of computing modules compatible with System/360 computers. Companies did not need to produce a whole computer anymore, all they had to do was sell separate compatible modules. This resulted in the even greater spreading of computers.
ASCII as the first information encoding standard
Teletype and terminal
At the same time, they were developing teletypes. It's a system that enables us to transmit text information at a distance. Two printers and two keyboards (typewriter-like keyboards powered by an electric motor) are connected by wires. The text typed on the keyboard of the first user is printed on the printer of the second user and vice versa. For instance, up until the early 1970s, a "hotline" between the US president and the USSR leadership was set up in this manner.
Teletypes also convert text information into some signals conveyed through wires. Yet binary code is not always in use, for example, Morse code is comprised of two signal units—dots and dashes, plus, of course, a pause. But teletypes require mapping tables containing the correspondence between characters and signals in wires. At the same time, each teletype (each pair of the connected teletypes) could have its own mapping tables, based on the tasks they address. For example, the language could differ, and therefore the character set itself, depending on the device. The most popular (frequently used) characters were encoded with the shortest set of signals to maximize the teletype workload, which means that the character set could vary even within the same language.
Teletypes were the foundation for creating terminal: no messages were sent to the second user by such a device. The data was input into a remote computer, which processed the commands, and provided the outcome as a response message. This innovation made it possible to use the computing power of computers that were very expensive at the time, without having physical access to the computer. For example, a computer could be located in a separate computing center or an institute, and employees from other branches or cities could access the computing power of that computer through installed terminals.
ASCII
The worldwide spread of computers and means of data exchange required the development of a universal character encoding standard for the transmission and storage of information. Such a standard was developed in the USA in 1963. The table of 128 characters was named ASCII (American Standard Code for Information Exchange).
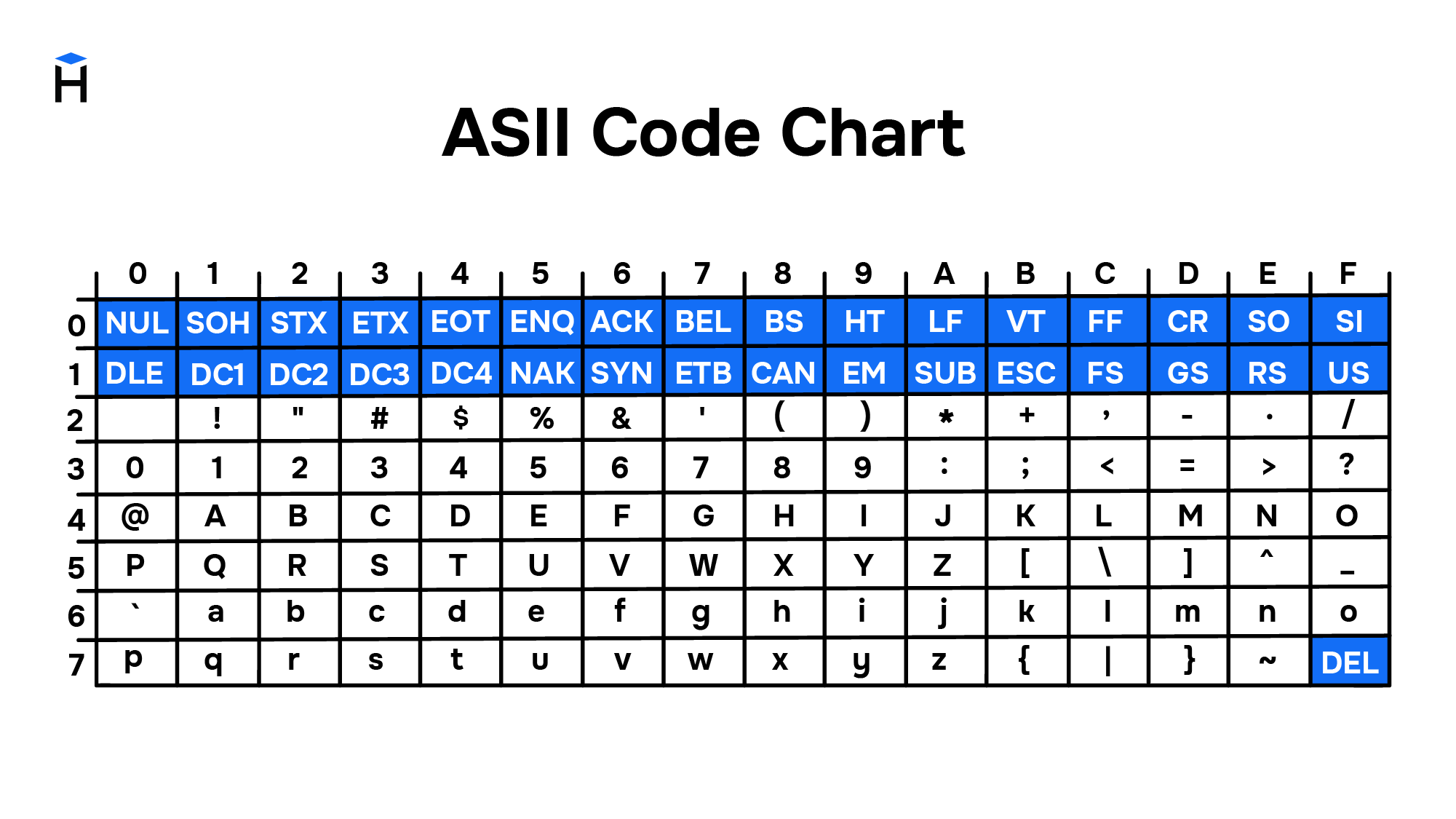
ASCII reserves the first 32 codes for control characters. They intend to control devices (such as teletype printers) and receive some composite characters. For example:
- the symbol Ø could be obtained as follows: print O, then use the BS code (BackSpace) to move back and print the symbol /,
- the symbol à could be obtained by typing BS `
- the symbol Ç could be obtained by typing C BS ,
The introduction of control characters made it possible to obtain new characters as a combination of existing ones without any additional mapping tables.
ASCII standard resolved this issue only in English-speaking countries. However, in countries with different writing (for example, Cyrillic in the USSR) the problem remained.
Switching to Unicode
The rise of the Internet, the proliferation of computers, and the availability of low-cost memory all contributed to encoding confusion. This was especially evident on the Internet when the text written on one computer had to be displayed correctly on many other devices. This became a huge problem both for programmers, who had to decide which encoding to use, and for end-users, who couldn't access the texts they needed.
As a result, in October 1991, the first version of the universal symbol table, called Unicode, was developed. It contained 7161 different characters from 24 different writings from around the world at the time.
Characters and languages from new languages have been added to Unicode over time. For instance, version 1.0.1 included more than 20,000 Chinese, Japanese, and Korean ideograms in mid-1992. The current version already contains more than 143,000 characters.
Unicode-based encodings
You may visualize Unicode as a large character table. The relevant numbers from the table, not the characters themselves, are stored in the computer's memory. They differ in the way the Unicode number is written as a set of bytes. They are called UTF — Unicode Transformation Format. There are fixed- and variable-length encodings. For example, UTF-32 uses only 4 bytes per each character, and UTF-8 (variable-length encoding), which became the most popular, uses 1-2 bytes for usual characters and 4 bytes for rare ones. For example, all the characters in the ASCII use just one byte, so text written in English using UTF-8 encoding will take up the same amount of space as text that is written using the ASCII Code.
But either way, everyone who works with computers and texts use Unicode. Unicode enables to use thousands of different characters and display them the same way on all devices from mobile phones to computers on space stations.
Summary
- Encoding is the correspondence between graphial characters and numbers
- Encodings are necessary because computers were meant to work with numbers and can't handle texts
- Until the 1990s there was no single encoding, which often made texts completely unreadable
- Unicode is the universal character representation standard. The Internet development and the need to exchange a large amount of text information resulted in its widespread use
- UTF-8, UTF-16, UTF-32 are Unicode-based encodings. The main difference between them is how many bytes it requires to represent a character in memory
- UTF-8 is the most widely used encoding: it uses 1-2 bytes for the usual characters, and 3-4 bytes for the rare ones. This saves a significant amount of memory, for example, when working with English text