
Что такое логирование

Известно, что программисты проводят много времени, отлаживая свои программы, пытаясь разобраться, почему они не работают — или работают неправильно. Когда говорят про отладку, обычно подразумевают либо отладочную печать, либо использование специальных программ – дебагеров. С их помощью отслеживается выполнение кода по шагам, во время которого видно, как меняется содержимое переменных. Эти способы хорошо работают в небольших программах, но в реальных приложениях быстро становятся неэффективными.
Сложность реальных приложений
Возьмем для примера типичный сайт. Что он в себя включает?
- DNS. Система трансляции имени сайта в ip-адрес сервера.
- Веб-сервер. Программа, обслуживающая входящие запросы, перенаправляет их в код приложения и забирает от приложения данные для пользователей.
- Физический сервер (или виртуальный) с его окружением. Включает в себя операционную систему, установленные и запущенные обслуживающие программы, например, мониторинг.
- База данных. Внешнее хранилище, с которым связывается код приложения и обменивается информацией.
- Само приложение. Помимо кода, который пишут программисты, приложение включает в себя сотни тысяч и миллионы строк кода сторонних библиотек. Кроме этого, код работает внутри фреймворка, у которого свои собственные правила обработки входящих запросов.
- Фронтенд часть. Код, который выполняется в браузере пользователя. И системы сборки для разработки, например, Webpack.
И это только самый простой случай. Реальность же значительно сложнее: множество разноплановых серверов, системы кеширования (ускорения доступа), асинхронный код, очереди, внешние сервисы, облачные сервисы. Все это выглядит как многослойный пирог, внутри которого где-то работает написанный нами код. И этот код составляет лишь небольшую часть всего происходящего. Как в такой ситуации понять, на каком этапе был сбой, или все пошло не по плану? Для этого, как минимум, нужно определить, в каком слое произошла ошибка. Но даже это не самое сложное. Об ошибках в работающем приложении узнают не сразу, а уже потом, — когда ошибка случилась и, иногда, больше не воспроизводится.
Логирование
И для всего этого многообразия систем существует единое решение — логирование. В простейшем случае логирование сводится к файлу на диске, куда разные программы записывают (логируют) свои действия во время работы. Такой файл называют логом или журналом. Как правило, внутри лога одна строчка соответствует одному действию.
# Формат: ip-address / date / HTTP-method / uri / response code / body size
173.245.52.110 - [19/Jan/2021:01:54:20 +0000] "GET /my HTTP/1.1" 200 46018
108.162.219.13 - [19/Jan/2021:01:54:20 +0000] "GET /sockjs-node/244/gdt1vvwa/websocket HTTP/1.1" 0 0
162.158.62.12 - [19/Jan/2021:01:54:20 +0000] "GET /packs/css/application.css HTTP/1.1" 304 0
162.158.62.84 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/runtime-eb0a99abbe8cf813f110.js HTTP/1.1" 304 0
108.162.219.111 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/application-2cba5619945c4e5946f1.js HTTP/1.1" 304 0
108.162.219.21 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/0564a7b5d773bab52e53.js HTTP/1.1" 304 0
108.162.219.243 - [19/Jan/2021:01:54:20 +0000] "GET /packs/js/6fb7e908211839fac06e.js HTTP/1.1" 304 0
Выше небольшой кусок лога веб-сервера Хекслета. Из него видно ip-адрес, с которого выполнялся запрос на страницу и какие ресурсы загружались, метод HTTP, ответ бекенда (кода) и размер тела ответа в HTTP. Очень важно наличие даты. Благодаря ей всегда можно найти лог за конкретный период, например на то время, когда возникла ошибка. Для этого логи грепают:
# Выведет 4 минуты логов за 31 марта 2020 года с 19:31 по 19:35
grep "31/Mar/2020:19:3[1-5]" access.log
Когда программисты только начинают свой путь, они, часто не зная причину ошибки, опускают руки и говорят «я не знаю, что случилось, и что делать». Опытный же разработчик всегда первым делом говорит «а что в логах?». Анализировать логи — один из базовых навыков в разработке. В любой непонятной ситуации нужно смотреть логи. Логи пишут все программы без исключения, но делают это по-разному и в разные места. Чтобы точно узнать, куда и как, нужно идти в документацию конкретной программы и читать соответствующий раздел документации. Вот несколько примеров:
Многие программы логируют прямо в консоль, например Webpack показывает процесс и результаты сборки:
# Сюда же выводятся ошибки, если они были
「wds」: Project is running at http://hexletdev4.com/
「wds」: webpack output is served from /packs/
「wds」: Content not from webpack is served from /root/hexlet/public/packs
「wds」: 404s will fallback to /index.html
「wdm」: assets by chunk 10.8 MiB (auxiliary name: application) 115 assets
sets by path js/ 13.8 MiB
assets by path js/*.js 13.8 MiB 52 assets
assets by path js/pages/*.js 5.1 KiB
asset js/pages/da223d3affe56711f31f.js 2.6 KiB [emitted] [immutable] (name: pages/my_learning) 1 related asset
asset js/pages/04adacfdd660803b19f1.js 2.5 KiB [emitted] [immutable] (name: pages/referral) 1 related asset
sets by chunk 9.14 KiB (auxiliary id hint: vendors)
Во фронтенде файлов нет, поэтому логируют либо прямо в консоль, либо к себе в бекенды (что сложно), либо в специализированные сервисы, такие как LogRocket.
Уровни логирования
Чем больше информации выводится в логах, тем лучше и проще отладка, но когда данных слишком много, то в них тяжело искать нужное. В особо сложных случаях логи могут генерироваться с огромной скоростью и в гигантских размерах. Работать в такой ситуации нелегко. Чтобы как-то сгладить ситуацию, системы логирования вводят разные уровни. Обычно это:
- debug
- info
- warning
- error
Поддержка уровней осуществляется двумя способами. Во-первых, внутри самой программы расставляют вызовы библиотеки логирования в соответствии с уровнями. Если произошла ошибка, то логируем как error, если это отладочная информация, которая не нужна в обычной ситуации, то уровень debug.
// Пример логирования внутри программы
// Логер: https://github.com/pinojs/pino
import buildLogger from 'pino';
const logger = buildLogger(/* возможная конфигурация */);
logger.info('тут что то полезное');
Во-вторых, во время запуска программы указывается уровень логирования, необходимый в конкретной ситуации. По умолчанию используется уровень info, который используется для описания каких-то ключевых и важных вещей. При таком уровне будут выводиться и warning, и error. Если поставить уровень error, то будут выводиться только ошибки. А если debug, то мы получим лог, максимально наполненный данными. Обычно debug приводит к многократному росту выводимой информации.
Уровни логирования, обычно, выставляются через переменную окружения во время запуска программы. Например, так:
# https://github.com/fastify/fastify-cli#options
FASTIFY_LOG_LEVEL=debug fastify-server.js
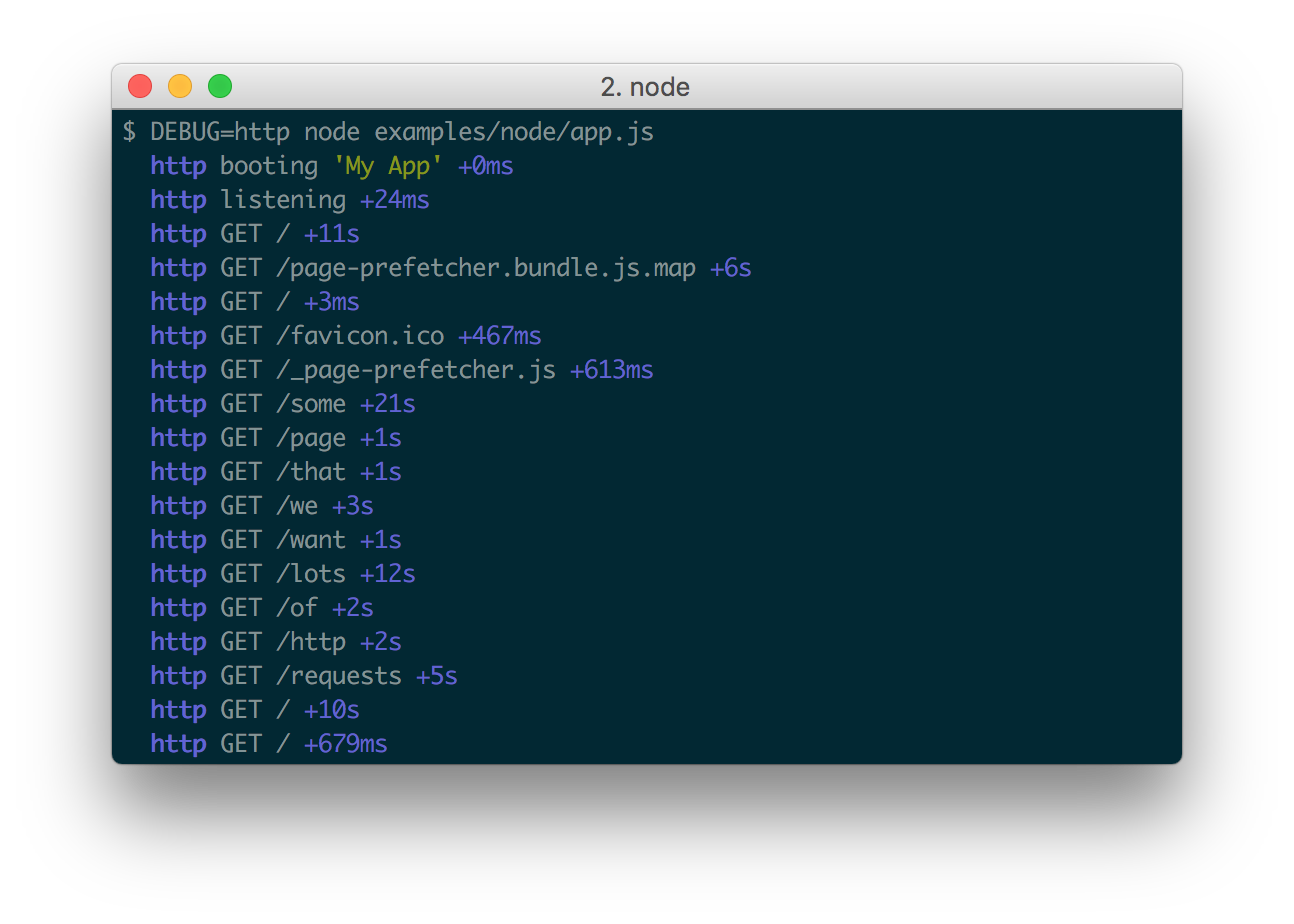
Существует и другой подход, основанный не на уровнях, а на пространствах имен. Этот подход получил широкое распространение в JS-среде, и является там основным. Фактически, он построен вокруг одной единственной библиотеки debug для логирования, которой пронизаны практически все JavaScript-библиотеки как на фронтенде, так и на бекенде.
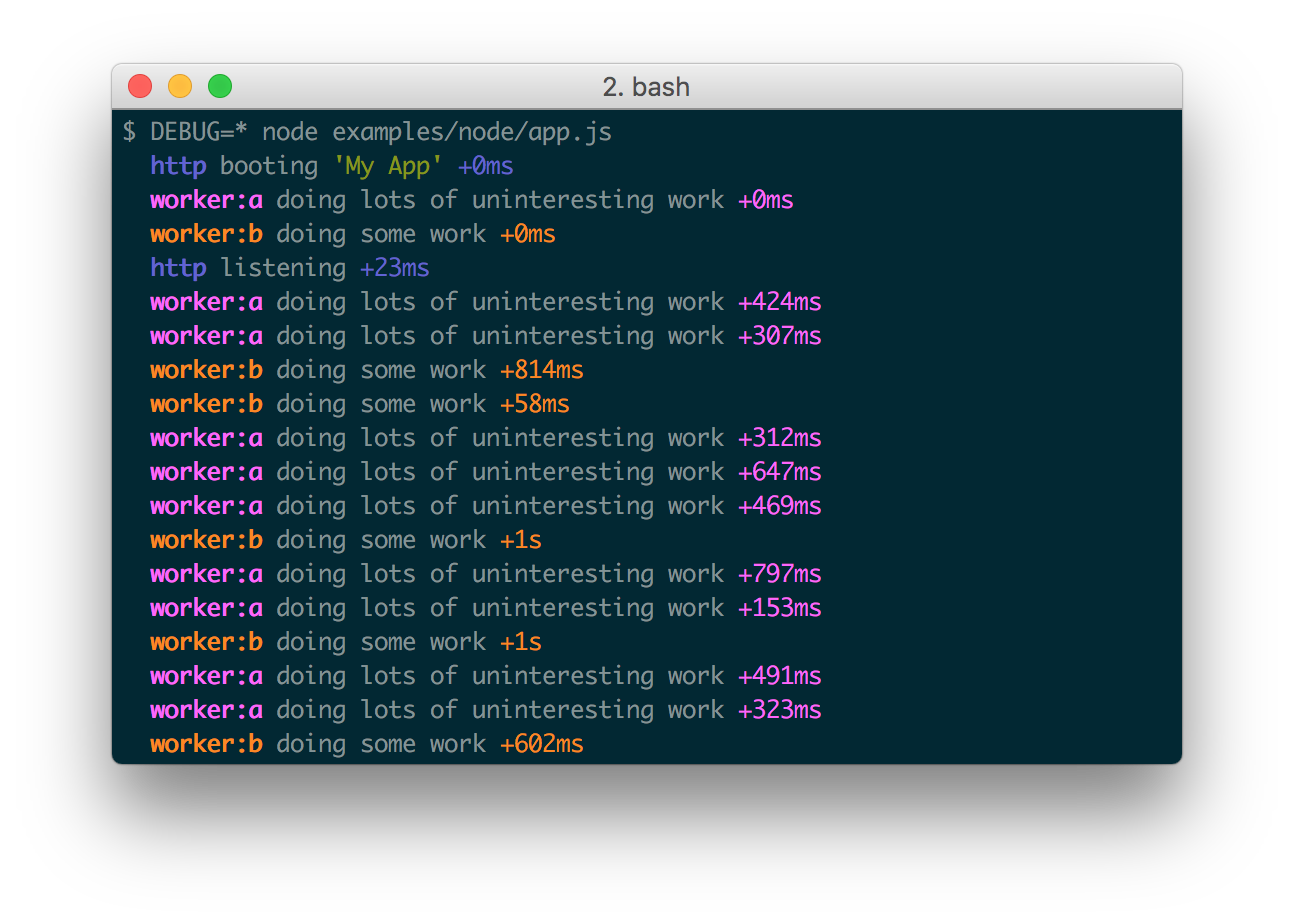
Принцип работы здесь такой. Под нужную ситуацию создается специализированная функция логирования с указанием пространства имен, которая затем используется для всех событий одного процесса. В итоге библиотека позволяет легко отфильтровать только нужные записи, соответствующие нужному пространству.
import debug from 'debug';
// Пространство имен http
const logHttp = debug('http');
const logSomethingElse = debug('another-namespace');
// Где-то в коде
logHttp(/* информация о http запросе */);
Запуск с нужным пространством:
DEBUG=http server.js
Ротация логов
Со временем количество логов становится большим, и с ними нужно что-то делать. Для этого используется ротация логов. Иногда за это отвечает сама программа, но чаще — внешнее приложение, задачей которого является чистка. Эта программа по необходимости разбивает логи на более мелкие файлы, сжимает, перемещает и, если нужно, удаляет. Подобная система встроена в любую операционную систему для работы с логами самой системы и внешних программ, которые могут встраиваться в нее.
С веб-сайтами все еще сложнее. Даже на небольших проектах используется несколько серверов, на каждом из которых свои логи. А в крупных проектах тысячи серверов. Для управления такими системами созданы специализированные программы, которые следят за логами на всех машинах, скачивают их, складывают в заточенные под логи базы данных и предоставляют удобный способ поиска по ним.
Здесь тоже есть несколько путей. Можно воспользоваться готовыми решениями, такими как DataDog Logging, либо устанавливать и настраивать все самостоятельно через, например, ELK Stack